ONCE-3DLanes
Introduction
ONCE-3DLanes dataset, a real-world autonomous driving dataset with lane layout annotation in 3D space, is a new benchmark constructed to stimulate the development of monocular 3D lane detection methods.
This dataset is constructed from ONCE, you can refer to our paper ONCE-3DLanes: Building Monocular 3D Lane Detection for the dataset construction details. It is collected in various geographical locations in China, including highway, bridge, tunnel, suburb and downtown, with different weather conditions (sunny/rainy) and lighting conditions (day/night).
The whole dataset contains 211K images with its corresponding 3D lane annotations in the camera coordinates.
Dataset Split:
- train: 200K
- val: 3K
- test: 8K
The resolution of images in this dataset is
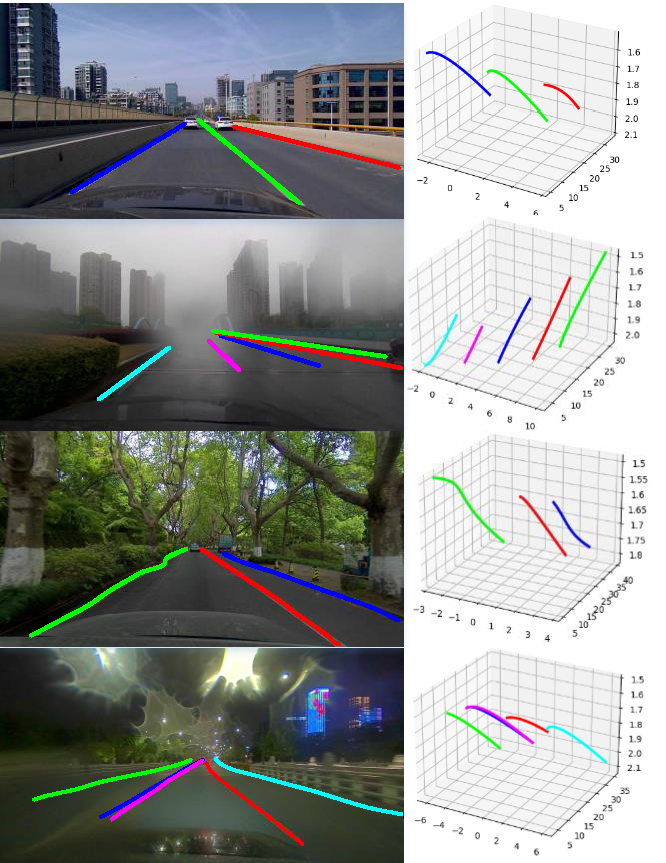
Some examples of our dataset are shown as below.
Descriptive statistical analysis
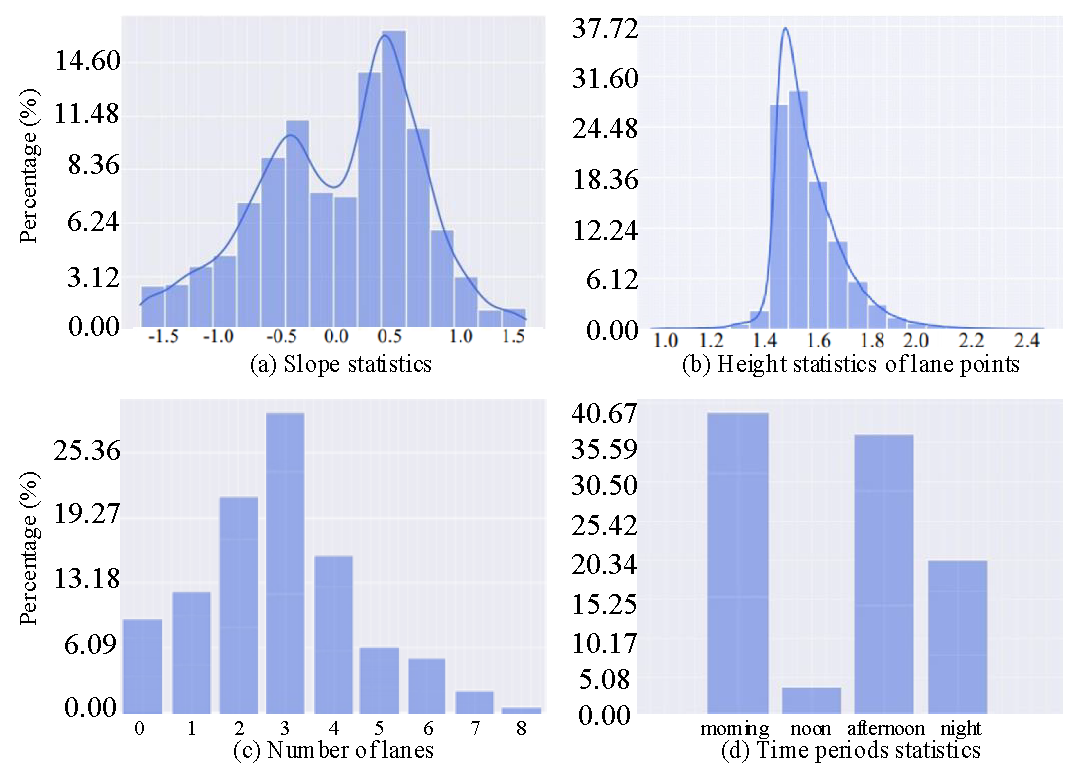
Our dataset contains enough slope scenes, different lighting conditions and the number of lanes shows the complexity of driving scenes in our dataset.
Annotations
The dataset contains three parts:
- train: labels and train.txt
- val: labels and val.txt
- test: test.txt
ONCE_3DLanes├─list/| ├─test.txt| ├─train.txt| └─val.txt├─val/| ├─000027/ #sequence/│ | ├─cam01/│ │ | ├─1616100800400.json #frame.json│ │ ...│ ├─000028/│ | ├─cam01/│ │ | ├─1616102048799.json│ │ | ...│ └─ ...└─train/| ├─000000/│ | ├─cam01/│ │ | ├─1616003650999.json│ │ | ...│ ├─000001/│ | ├─cam01/│ │ | ├─1616004779000.json│ │ | ...│ └─ ...
- list/ : this folder contains three txt files of train/val/test split, each txt file contains the path of this part of the data. You can easily index the required images under the ONCE dataset and the labels under the ONCE_3DLanes dataset through this path.
- val/: this folder contains several sequences, which belong to validation dataset. Each sequence contains the labels of all frames in this sequence. 3D lane labels of each frame are saved in the frame.json file.
- train/: the structure of this folder is the same as the val/ folder, which contains the train dataset information.
Data Format:
Each frame has an image, for each image, there would be a frame.json file, the number of lanes in this image is counted as lane_num. Each lane is represented as a series of key points with the x, y, z coordinates in the camera coordinates.
xxxxxxxxxx{ "lane_num": 4 # number of lanes in this image "lanes":[ # One lane [ # The [x, y, z] coordinates of key points in the lane are listed as follows and each lane has at least two key points. [-2.475, 1.871, 31.082], [-2.547, 1.854, 28.394], ... ] ... ] "calibration": [[958.3320922851562, -0.1807, 934.5001074545908, 0.0], [0.0, 961.3646850585938, 518.6117222564244, 0.0], [0.0, 0.0, 1.0, 0.0]] # the camera intrinsics }Coordinates: In the camera coordinates, the x-axis points to the right of the vehicle, the Y-axis points to the front, and the Z-axis points to the bottom.
We also provide the code to read the labels, you can directly read the 2D lane and 3D lane labels of the image from the frame.json file.
Downloads
We don't provide the images and you can download the images in the ONCE_Download, you can easily index the required images with our image path in txt files.
The 3D lane labels of our ONCE_3DLanes dataset is about 141.5 MB after compression.
We provide download link from Google Drive and Baidu Yunpan to facilate users from all over the world.
Extraction code : 1234
Evaluation Tools
We also provide the evaluation tools here
Baseline Results
Comparison of Monocular 3D lane detection methods
We show the evaluation results of our method SALAD, as well as two other monocular 3D lane detection methods.
- "3d-lanenet: end-to-end 3d multiple lane detection", N. Garnet, etal., ICCV 2019
- "Gen-LaneNet: a generalized and scalable approach for 3D lane detection", Y. Guo, etal., ECCV 2020
| Method | F1(%) | Precision(%) | Recall(%) | CD error(m) |
|---|---|---|---|---|
| 3D-LaneNet | 44.73 | 61.46 | 35.16 | 0.127 |
| Gen-LaneNet | 45.59 | 63.95 | 35.42 | 0.121 |
| SALAD | 64.07 | 75.90 | 55.42 | 0.098 |
Comparison of extended 2D lane detection methods
We also extend some 2D lane detection methods with depth estimation to perform 3D lane detection task, the comparison results are shown in the table below.
| Method | F1(%) | Precision(%) | Recall(%) | CD error(m) |
|---|---|---|---|---|
| PointLaneNet (R101) | 54.99 | 64.50 | 47.93 | 0.115 |
| UltraFast (R101) | 54.18 | 63.68 | 47.14 | 0.128 |
| RESA (R101) | 55.53 | 65.08 | 48.43 | 0.112 |
| LaneAF (DLA34) | 56.39 | 66.07 | 49.18 | 0.109 |
| LaneATT (R122) | 56.57 | 66.75 | 49.07 | 0.101 |
| SALAD | 64.07 | 75.90 | 55.42 | 0.098 |
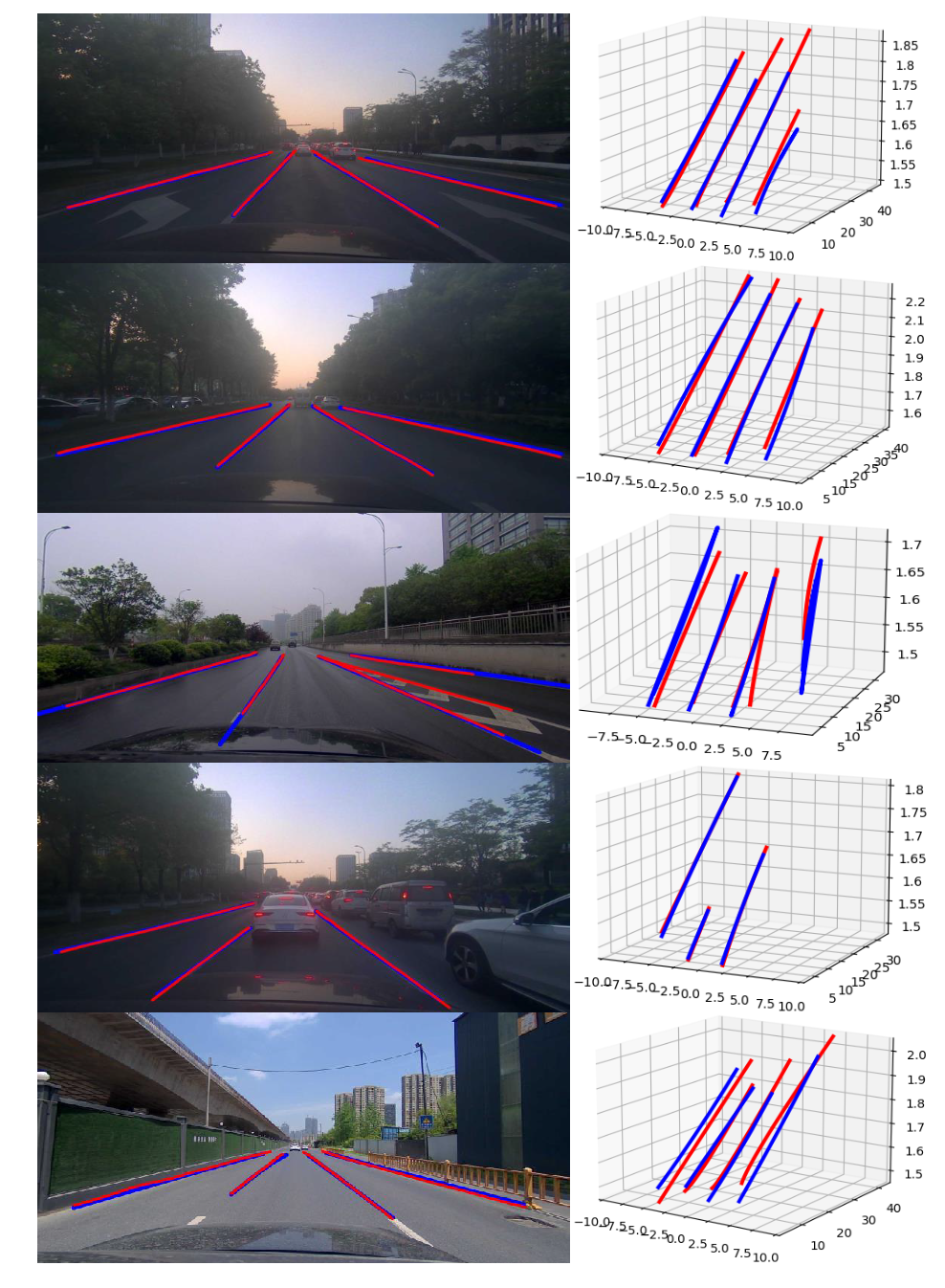
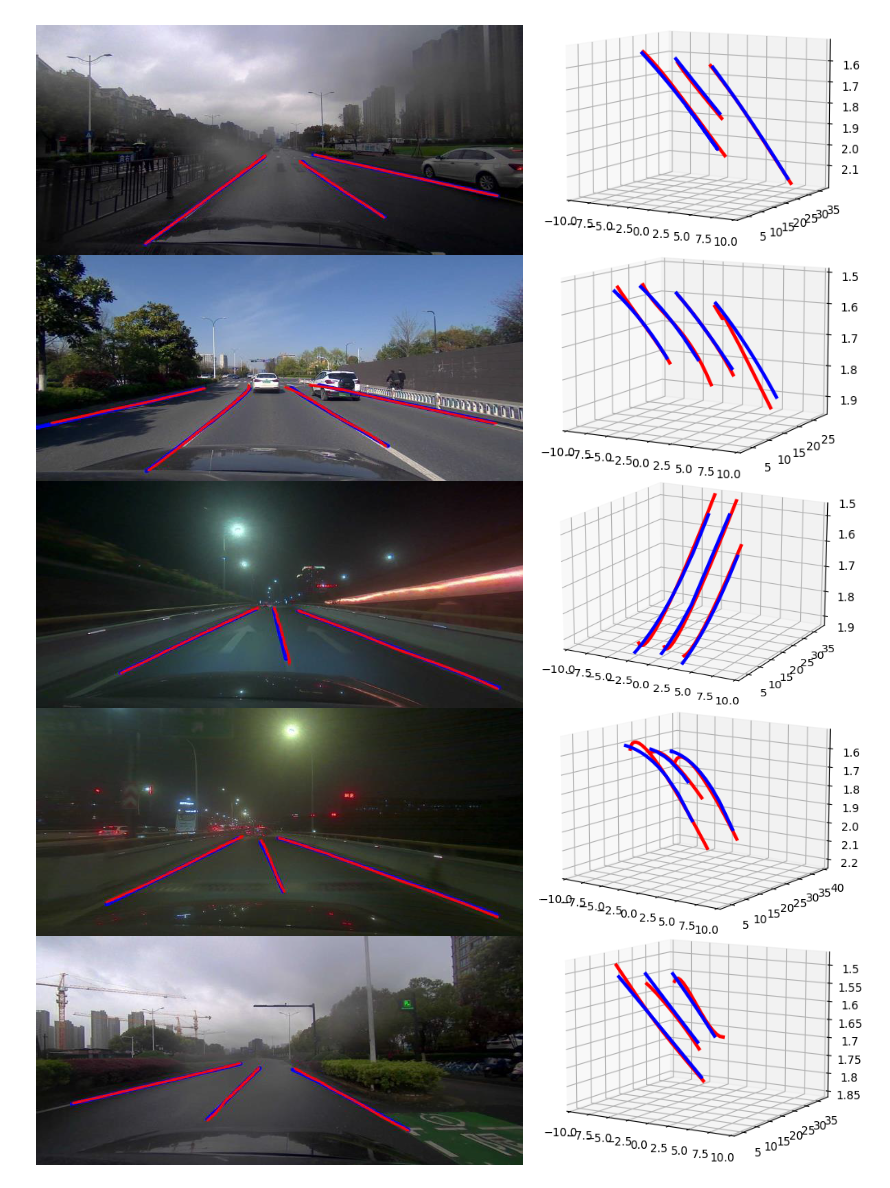
Visualization
We show several examples in testing dataset with different lighting conditions.
The ground-truth lanes are colored in red while the predicted lanes are colored in blue.
2D projections are shown in the left and 3D visualizations in the right.
Citation
Please cite this paper in your publications if it helps your research:
xxxxxxxxxx@InProceedings{yan2022once,title={ONCE-3DLanes: Building Monocular 3D Lane Detection},author= {Yan, Fan and Nie, Ming and Cai, Xinyue and Han, Jianhua and Xu, Hang and Yang, Zhen and Ye, Chaoqiang and Fu, Yanwei and Michael,Bi Mi and Zhang, Li},booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},year={2022},}